Strategy Inference
I am a designer/developer in the Strategy Inference Vertically Integrated Project (VIP) working under Dr. Narayana Santhanam.
The purpose of our project is to use machine learning models to allow a computer to strategize against a human opponent in a checkers-like game called Huligutta. We also aim to learn about key machine learning and neural network concepts, as well as programming concepts and strategies for dealing with large data sets. This will be achieved through a combination of Python 3 and an assorted collection of libraries for Python, including Numpy, Tkinter and Tensorflow. We have explored Reinforcement Learning and aim to incorporate Ensemble Learning through a process called Bagging.
Gameplay
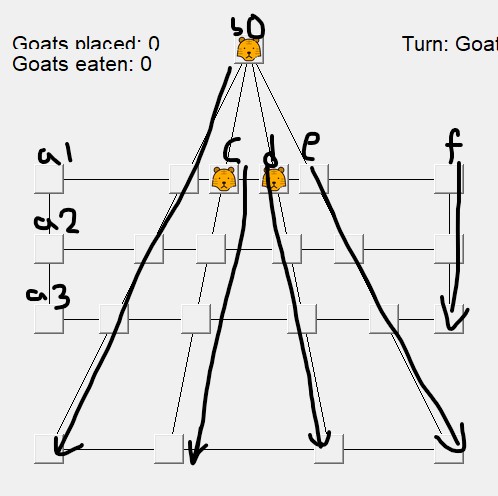
The game we are working with is called Huligutta, or Goats and Tigers, a game which involves two players playing asymmetrically. That is, they each have different pieces and different goals. One side controls three tigers, whose goal is to eat five goats. The tigers can eat goats by jumping over them, much like in checkers. The other side controls up to 15 goats, who start out off the board. The player takes 15 turns placing the goats, then moves the goats around after all have been placed. The goal for the goats is to block in all the tigers so they have no moves. The layout of the board can be seen below, and the values assigned to each positioned have been labeled.
My roles
In this project my main goal is to create a machine learning model which will determine a strategy for the computer controlled side of our game. Some additional goals are making the game run smoother, as well as making the interface look more professional and reducing the number of bugs in the system. I am currently in the process of developing an algorithm which will determine a value based on any current state of the board, which works by adding positive value when there is a beneficial situation for the goats and adding negative value when there is a beneficial situation for the tigers. This will be used to determine a next move based on how it will affect the value of the board state, and will be pitted against other algorithms designed by two other teams in our project.
I have designed a neural network designed to take in the positions of all pieces on a board with the target as which tiger to move. My network currently attempts to determine which tiger to then move given the positions of all pieces. In the first layer we have linear activation with l2 regularization and in the second hidden layer we have the ReLU activation. For the loss we used a combined loss of Hinge and Cross Entropy in place of using Hinge for the first layer to mimic an SVM and Cross Entropy for the remaining layers. This was the goal but we were not able to figure out how to do this in time. Further work is needed to design a second network to then decide the best place to move the chosen tiger.